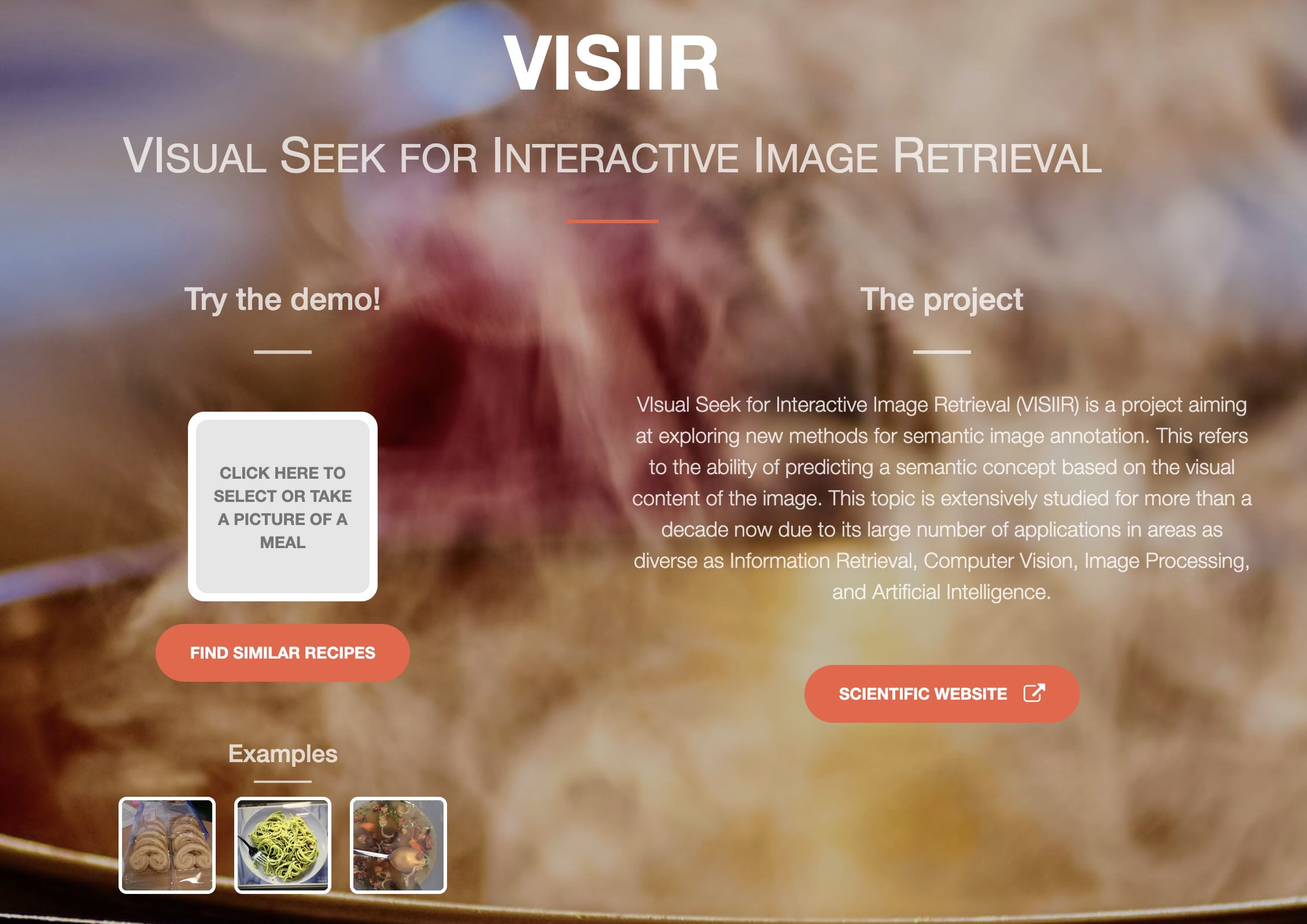
Demo Foodingue!
Amazing Sorbonne Univ collection (MNHN)



News Archives
2023
Main publi/infos:
3 NeurIPS OBELICS, Rewarded soups and REx: Data-Free Quantization
2 ICCV eP-ALM: Efficient Perceptual Augmentation of Language Models and ZestGuide accepted to ICCV 2023 in Paris!
1 paper UnIVAL: Unified Model for Image, Video, Audio and Language Tasks accepted to MMFM Workshop @ICCV.
1 ICML Model Ratatouille: Recycling Diverse Models for ood
4 CVPR
Counterfactual Explanations,
Semantic and Panoptic Segmentation,
Visual Recognition,
Improving Selective VQA
2 ICLR Image editing with diffusion models and Data free quantization of deep nets
1 IJCV paper on Explainability of vision-based autonomous driving systems: Review and challenges
AndrewYNg’s news letter pointed out our recent strategy for training Transformers in Vision: Cookbook for Vision Transformers: Good insight about our DeiT III !
2022
Main publi/infos:
Dec.: 2 papers presented at NeurIPS, 1 paper at CoRL
Nov.: 1 paper at BMVC Conference Efficient Vision-Language Pretraining with Visual Concepts and Hierarchical Alignment!
Oct: 3 papers presented at ECCV including STEEX! and 2 papers about DeiT
July: 1 paper at ICML Fishr: Invariant Gradient Variances for Out-of-distribution Generalization
June: 2 papers at CVPR 1- Flexible Semantic Image Translation, 2- Transformers for continual learning + 8 workshop papers:
T-FOOD Transformer for Cross-Modal Food Retrieval,
Raising context awareness in motion forecasting,
Embedding Arithmetic of Multimodal Queries for Image Retrieval,
Towards efficient feature sharing in MIMO architectures,
Dynamic Query Selection for Fast Visual Perceiver,
Swapping Semantic Contents for Mixing Images,
Multi-Head Distillation for Continual Unsupervised Domain Adaptation in Semantic Segmentation
and RED++: Data-Free Pruning of Deep Neural Networks via Input Splitting and Output Merging published T-PAMI
Janv. 2022 MLIA is joigning the ISIR lab of Sorbonne University, it is a fantastic opportunuity with a lot of new challenges for us!
2021
Main publi/infos:
2 NeurIPS – Data-Free Compression of Deep Neural Networks and on Efficient Black-box Explanations for deep nets
5 ICCV – domain adaptation, bias, Mixing and data augmentation, self supervised, transformers (Xtarget Domain adaptation, Bias and Xmodal shortcuts, CaiT Deeper with transformers, Deep ensembles with 1 net, Coarse labels but fine-grained classification )
1 ICML – DeiT data-efficient image transformers
3 CVPR – Continual Semantic Segmentation, Semantic editing GANs, and Self Supervised BoW + workshops: Insights from the Future for Continual Learning at CVPR workshop on continual learning in computer vision, Learning Reasoning Mechanisms for Unbiased Question-based Counting at CVPR workshop on VQA
1 ICLR – diversity in deep ensembles
1 BMVC – GAN editing
1 PAMI – confidence for deep
and others …
1 IEEE Trans on Intelligent Transportation Systems – Detecting 32 Pedestrian Attributes for Autonomous Vehicles
1 CVIU zero-shot semantic segmentation with domain adaptation published in CVIU
1 paper BEEF on XAI and Autonomous driving at the NeurIPS workshop: Machine Learning for Autonomous Driving
2020
Main publications:
2 ECCV papers accepted on PODNet incremental learning and Knowledge distillation
1 CVPR paper accepted on self learning: Learning Representations by Predicting Bags of Visual Words
1 PR Journal paper on semantic segmentation SEMEDA
1 ICASSP paper on GAN: This dataset does not exist: training models from generated images
1 AAAI paper accepted on our GAN strategy for Cross-Channel Image Completion
Participation of PhD defenses in 2020: Benjamin Piwowarski (HDR 10/23), Srijan Das (10/01), Thomas Lucas (09/25), Yifu Chen (09/09), Pierre Jacob (08/09), Rémi Cadene (07/08), Daniel Brooks (07/03), Mickaël Chen (07/02), Martin Engilberge (06/12), Adrien Poulenard (04/15)
2019
Main publications:
4 NeurIPS (NIPS) – Bias in VQA, zero-Shot Segmentation, Failure Detection, Riemannian NNets
4 ICCV – UDA, Face alignment, Few-shot, 3D manifold learning
3 CVPR – SoDeep, Advent and MUREL
1 AAAI – Tensor decomposition
Oct.
ICCV conf.
PhD defense of E. Mehr with MP. Cani, L. Guibas, T. Boubekeur, K. Bally, M. Ovsjaniko, V. Guiteny, M. Cord (Supervisor)
PhD defense of T. Robert with S. Canu, G. Mori, C. Achard, K. Amahari, D. Picard, N. Thome, M. Cord (Supervisor)
Sept.
4 NeurIPS (NIPS) accepted! Biais in VQA, 0-Shot Segmentation, Failure Detection, Riemannian NNets
Aug.
PhD defense of J. Peyre, with J. Sivic, C. Schmid, I. Laptev, F. Jurie, S. Lazebnik, M. Cord (Rev)
July
4 ICCV accepted!
PhD defense of Junhao Wen with F. Barkhof, P. Coupé, O. Commowick, O. Colliot, S. Durrleman, M. Cord (President)
June
CVPR conference
May
PhD defense of H. Ben-younes Multi-modal representation learning towards visual reasoning with Y. Lecun, J. Verbeek, V. Ferrari, C. Wolf, P. Perez, L. Soulier, N. Thome, M. Cord (Supervisor)
March
3 CVPR SoDeep, Advent and MUREL accepted this year including 2 oral!
PhD defense of Arthur Guillon with N. Labroche, J. Velcin, A. Cornuéjols, C. Frélicot, MJ. Lesot, C. Marsala, M. Cord (President)
Feb
HdR defense of K. Bailly with L. Heutte, JM. Odobez, B. schuller, M. Chetouani, M. Cord (Pres), J. Crowley
Jan
Our PAMI,IJCV and Neurocomputing journal papers online in my publication page!
Our CVPR 2018 code on multimodal (text+im)embedding online
2018
- Dec
- Neurips presentation of our poster Revisiting Multi-Task Learning with ROCK
- PhD defense of J. Ogier du Terrail with E. Fromont, S. Lefevre, F. Jurie, M. Cord (Pres), F. Oudyi
- PhD defense of K. Blanc with F. Bremond, B. Merialdo, T. Menguy, N. Thome, M. Cord (Rev), D. Lingrand
- PhD defense of M. Carvahlo Deep space representation with L. Soulier, E. Gaussier, S. Lefevre, F. Precioso, H. Leborgne, N. Thome, M. Cord (Supervisor)
- Nov AAAI 2019: our paper BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection accepted!
- PhD defense of T. Mordan Designing deep architectures for visual understanding with F. Perronnin, J. Sivic, A. Alahi, N. Neverova, N. Thome, M. Cord (Supervisor)
-
PhD defense of M. Blot Study on training methods and Generalization performances of deep learning with A. Rakotomamonjy, C. Wolf, E. Fromont, A. Bellet, L. Ralaivola, N. Thome, M. Cord (Supervisor)
-
Oct ICIP 2018: BEST PAPER AWARD for our paper SHADE: INFORMATION-BASED REGULARIZATION FOR DEEP LEARNING!
- Sept NIPS 2018: our paper Revisiting Multi-Task Learning with ROCK: a Deep Residual Auxiliary Block for Visual Detection accepted!
- July ECCV 2018: our paper HybridNet: Classication and Reconstruction Cooperation for SSL accepted
- June RFIAP conference: with 3 invited speakers: A. Alahi, Y. LeCun, Maja Pantic
- PhD defense of H. Jain with E. Kijak, F. Jurie, M. Cord(R), F. Perronnin(R), P. Perez, C. Guillemot, R. Gribonval, H. Jégou
- PhD defense of Y. Tamaazousti with I. Kokkinos, PH. Gosselin, C. Hudelot, H. Leborgne, M. Cord(P), P. Piantanida, F. Perronnin
- May PhD defense of B. Moysset with E. Fromont, L. Heutte, C. Couprie, C. Wolf, C. Kermorvant, M. Cord (Pres)
- April Our paper Cross-modal retrieval in the cooking context: Learning semantic text-image embeddings accepted as a full paper for oral presentation at the SIGIR 2018! completed with an ICDE 2018 workshop paper dedicated on computational cooking scenarios
- April Entretien sur France Culture avec René Frydman
- March 2 papers accepted at CVPR 2018!
-
March Our TNNLS paper SyMIL: MinMax Latent SVM for Weakly Labeled Data, with T. Durand and N. thome accepted!
- Feb DeepVision Workshop in Vancouver
- Jan PAMI paper on Negative Evidence for Deep Latent Structured Models accepted!
2017
- Dec 19 PhD defense of R. Rezende with P. Perez, F. Perronin, J. Ponce, F. Bach, F. Jurie, M. Cord (Pres)
- Nov 20 Talk at Deep Learning UPMC
- Nov 09 VQA Talk at INRIA Sophia
- Nov 09 PhD defense of M. Koperski with JM Odobez, F. Precioso, F. Bremond, M. Cord (rev), L. Sigal, F. Gianpiero
- Nov 02 and 03 deep learning course at Institut d’automne de l’IA, Lyon
- Oct 06 PhD defense of E. Oyallon with P. Perez, F. Perronin, S. Mallat, I. Laptev, N. Paragios, M. Cord (Pres)
- Oct Talk on Visual Question Answering VQA in FranceIsIA event, Paris
- Sept 29 PhD defense of my Student X. Wang with F. Precioso, N. Thome, M. Cord, P. Le Callet, C. Achard, C. Wang, PH. Gosselin
- Sept 20 PhD defense of my Student T. Durand with F. Bach, C. Schmid, N. Thome, M. Cord, P. Perez, A. Rakotomamonjy, V. Serfati (Invited)
- Sept BMVC 2017 Best Science paper Award for our paper DEFORMABLE PART-BASED FULLY CONVOLUTIONAL NETWORK FOR OBJECT DETECTION
- July ICCV 2017 paper on Tensor decomposition for VQA task accepted
- July BMVC 2017 paper deep architecture for detection accepted
- July CVPR WILDCAT paper presentation, VQA workshop (Challenge VQA2)
- June Invited speaker, deep learning session in Big data advanced school, San Carlos, Brazil
- Feb Talk on Global average pooling in deep ConvNets at THOTH INRIA grenoble
- Feb, 06: PhD def. of M. Paulin with J. Sivic, V. Lepetit, C. Wolf, F. Perronnin, J. Mairal, C. Schmid, Z. Harchaoui, M Cord (Reviewer)
- Jan, 23: PhD def. of P. Kulkarni with P. Perez, F. Jurie, S. Canu, J. Zepeda, J. Verbeek, M Cord (Reviewer)
2016
- Dec., 2016: Invited speaker in Panel session in Future of Emerging Technologies – Memristors and Machine Learning, in 23rd IEEE International Conference on Electronics Circuits and Systems (ICECS), Monte Carlo, Monaco
- Dec., 2: PhD def. of M. Chevalier with S. Canu, F. Bremond, C. Achard, P. Perez, M. Cord, G. Henaff, N. Thome
- Nov., 3: PhD def. of J. Pasquet with M. Chaumont, C. Garcia, M. Cord, V. Charvillat, G. Subsol, P. Poncelet
- Oct., 2016: Invited talk in Symposium on Deep Learning and Artificial Intelligence, Tokyo, Japan
- Oct., 2016: Invited talk Deep learning and weak supervision for visual recognition in GdR ISIS workshop
- June, 2016: 2 papers accepted at CVPR 2016
- June 8, 2016: Talk at INRIA Thoth symposium on Computer Vision and Deep Learning
- June 7, 2016: HDR defense of Jakob Verbeek with M. Cord (reviewer), A. Zisserman, E. Gaussier, E. Learned-Miller, C. Schmid, T. Tuytelaars.
- May 19, 2016: Talk at I3S lab. on deep and weak supervision
- April 14, 2016: Half Day Deep learning Workshop (2nd edition) with GdR-ISIS at UPMC
- Introduction by M. Cord
- Plenary Talk of Yann LeCun (Facebook AI research, NYU, College de France) on predictive learning
- Poster session
- March 8, 2016: PhD def. of J. Nicolle with M. Cord (Pres), JP Thiran, B. Schuller, C. Garcia, K. Bailly, M. Chetouani
- Feb, 2016: (Press) France Culture Radio show on Lecun and deep learning and broccoli…
2015
- Dec: Paper on min-max LSSVM for classification & ranking presented at ICCV 2015 conf.
- Sept, 7: Tutorial with Aurélien Bellet on Metric Learning at ECML-PKDD, link to talks
- Sept, 3: Invited talk at the SMART summer school
- Aug, 31: PhD def. of Christion A. Kuoman with M. Cord (Pres), S. Tollari, M. Detiniecki, Ph. Mulhem, A Popecu, B. Ionescu
- July, 1: HDR def. of N. Thome with C. Schmid, N. Paragios, M. Cord (Pres), S. Canu, F. Jurie, S. Marchand-Maillet
- June, 30: PhD def. of C. LeBarz with F. Brémond, L. Denoyer, N. Thome, M. Cord, JY. Dufour, D. Filliat, S. Herbin
- June: seminar in Brazil, UNICAMP and UFMG
- Apr, 28: seminar at The Hong Kong Polytechnic University while visiting Lei Zhang colleague
- March, 20: Half Day Deep learning Workshop with GdR-ISIS
- Feb, 02: invited talk at the LIRIS monthly seminars on visual metric learning
- Jan, 22: PhD def. of A. Sanoja with M. Cord (Pres), M. Rukoz, E. Murisasco, L. Bouganim, P. Senellart, S. Gancarski
- Jan, 20: PhD def. of M. Law with F. Bach, F. Precioso, J. Ponce, P. Perez, P. gallinari, M. Cord, S. Gancarski, N. Thome
- Jan, 15: PhD def. of I Mhedhbi with P. Garda, A. Beghdadi, H. Rabbah, K. Hachicha, A. Bensrhair, D. Heudes, S. Hochberg, M Cord (President)
2014
- Dec: PhD Thesis of Hanlin Goh Learning deep visual representations
- Dec: our CVPR 2014 paper on fantope available
- Dec, 02: HDR def. of M. Visani with I. Bloch, F. Sedes, R. Ingold, JM. Ogier, K. Tombre, JM. Jolion, M. Cord (Pres)
- Oct, 06: HDR def. of V. Courboulay with JP Domenger, C. Fernandez-Maloigne, P. Le Callet, A. Guerin, M. Cord (Reviewer), A. Tabbone, A. Revel
- Sept: 02-03 Invited speaker at the first Franco-Taiwanais workshop at EURECOM Sept, 29: PhD def. of A. Cahn Hon Tong with S. Canu, A. Caplier, M. ElYacoubi, C. Achard, L. Lucat, M Cord (Pres)
- Sept, 16: HDR def. of S.A. Berrani with, T. Ebrahimi, N. Boujeemaa, M. Cord (Rev), B. Merialdo, P. Gros, J. Carrive, Ph. Joly
- Sept: 05-PhD def. of D. Awad with F. Precioso, A. Revel, V. Courboulay, M. Cord, B. Girau
- June, 13: PhD def. of A. Fagette with I. Laptev, L. Wong (NUS) F. Moutarde, O. Koch, D. Racoceanu, J Dufour, M. Cord (Pres)
- May, 13: PhD def. of A. Bourrier with P. Perez, R. Gribonval, F. Bach, E. LePennec, G. Blanchard, M. Cord (Chair)
- April, 15: Talk at Lyon LIMA2
- April, 9: PhD def. of M. Jain with A. Smeulders, C. Schmid, P. Perez, P. Bouthemy, P. Gros, H. Jegou, M. Cord (reviewer)
- April, 3: PhD def. of M. Jiu with C. Schmid, G. Taylor, M. Rombaut, A. Baskurt, C. Wolf, M. Cord (reviewer)
- March, 31: PhD def. of DP Vo with H. Sahbi, J. Benois-Pineau, C. Djeraba, F. Jurie, JM Ogier, M. Cord
- Feb, 17-18: SCAPE project meeting
- Feb, 11: PhD def. of A. Znaidia with H. Maitre, B. Merialdo, P. Lambert, S. Ayache, S. Marchand-Maillet, N. Paragios, C. Hudelot, H. Le Borgne, M. Cord
- Janv, 6: PhD def. of Z. Akata with C. Lampert, C. Schmid, V. Ferrari, F. Perronnin, G Quenot, M. Cord (reviewer)
2013
- Dec: NIPS conf presentation of our paper on deep learning
- Dec: Talk at Google, Mountain View on metric learning
- Nov, 12: Final presentation for ANR GeoPeuple Detection
- Oct, 11: PhD def. of Pehlivan Zeynep
- Oct, 09: PhD def. of P. Phothisane with T. Chateau, R. Seguier, M. Cord, K. Bailly, L. Prevost, E. Bigorne
- Oct, 02: PhD def. of LAI Hien Phuong about interactive CBIR with C. garcia, F. Sedes, B. Merialdo, M. Cord, JM Ogier, M Visani, A Boucher
- Sept: Invited talk in ERMITES summer school
- Sept, 30: PhD def. of my student Denis Pitzalis with N. Paparoditis, F. Niccolucci, F. Precioso, M. Joly and M. Detyniecki
- Sept: 1 paper accepted at NIPS 2013
- Sept: 1 paper accepted at ICCV 2013
- Aug: Rodrigo Minetto First place of PhD Thesis of SIBGRAPI 2013
- July, 12: PhD def. of my student Hanlin Goh with Y. Lecun, F. Jurie, A. Rakotomamonjy, JH. Lim as external members
- July, 9: PhD def. F. Martinez on Eye tracking with L. Chen, JM Odobez, A. caplier, F. Brémond, M. Cord as external members
- June, 27: Poster CVPR on learning local motion descriptors for video classification
- June, 14: PhD def. of my student Sandra Avila ! with C. Schmid, F. Perronnin, P. Perez, M. Campos, and P. Gallinari (+superv.)
- June, 5: PhD def. M. Trad on multimedia mining (chair) with B. Merialdo, A. Joly, N. Boujemaa, F. Precioso, D. teyssou, M. Cord
- May, 21: PhD Def. of Alina Abduraman on TV content analysis with M. Cord (chair), B. Merialdo, Ph. Joly, G. Gravier, J. Carrive, S. Berrani
- Jan: Session (Math. and Computer Science) chairman, JFFoS sympoqium, Kyoto Japon
- Introduction by M. Cord Speakers: T. Harada and I. Laptev
- Jan: JMLR paper accepted in JMLR Track for Machine Learning Open Source Software project
2012
- Dec, 20: talk at GdR Isis workshop
- Dec, 13: seminar at Columbia Univ., NY, USA
- Dec, 12: talk at ICMLA conf. Buca Raton, Fl, USA
- Dec, 07: HDR def. of Antoine Manzanera with P. Bouthémy, M. Couprie, M. Cord, JM Jolion, B. Zavidovique, M. Paindavoine
- Oct, 23: PhD Def. of MM Ullah on Human Action Recognition in Video (reviewer), with P. Perez, I. Laptev, F. Precioso, T. Tuytelaars, P. Bouthemy, E. Kijak
- Oct, 15: Keynote speaker at 2nd Singaporean-French IPAL Symposium
- Oct, 7-13: ECCV conf, poster presentation
- Sept: PhD Def. of Roxana Horincar on dynamic Web content analysis (chair),
- Sept: PhD Def. of Bahjat Safadi on semantic indexing of videos (reviewer)
- Aug: ERMITES summer school
- July: seminar in CNRS Summer School on Images, Content, recognition, classification
- June: Workshop SCAPE in Paris
- May, 23: INRIA Sophia seminar (Stars team) on Beyond the Bag of Word representation for image classification
- May, 2: PhD defense (reviewer) of JP. Burochin, with P. Sturm, C. Heipke, F Tupin, N. Paparoditis, O. Tournaire
- April, 3: PhD defense (reviewer) of Chao Zhu, with Liming Chen, CE Bichot, C Schmid and J. Benoit-Pineau
- March, 19: PhD defense of my student Rodrigo Minetto with Patrick Perez and Marcin Detyniecki for the french side and Jorge Stolfi and 3 colleagues in Brazil
- Feb: 1 paper accepted at ESANN 12 on learning product combinations of kernels with D. Picard, N. Thome and A. Rakotomamonjy
2011
- Dec: seminar at Columbia university and visit of the Prof. Chang’s DVMM lab
- Dec: seminar at NYU
- Dec: PhD Def. of Alex Spengler on Web content analysis (chair),
- Dec: PhD Def. (reviewer) of V. Dovgalecs
- Nov: PhD Def. (chairman) of J. Defretin
- Nov: Talk at ICCV workshop on Text Detection SnooperPlus.pdf
- Nov: Poster at ICCV workshop on kernel learning cordWshopIccv.pdf
- Oct: Talk at I3S lab., Sophia Antipolis Talki3sOct2011.pdf
- Oct: Steve Jobs papers lemonde, libe
- Oct: SCAPE Workshop at UPMC: Web page comparison talk
- Sept: 2 papers accepted to workshops at ICCV 2011
- Sept: ICIP conf. in Bruxelles
- Sept: Midterm defense on deep architectures for image, Hanlin Goh midterm.pdf
- Sept: Midterm evaluation of ANR ASAP slidesASAPmiparcours.pdf
- August: paper on chi2 LSH accepted to PAMI
- June: PhD Def. of Shuji Zhao
- May: Yann LeCun invited in LIP6 for 1 month Talk_1.pdf
- March: IGN french presentation on our text detection system IGNcord.pdf
- Feb: Kick-off meeting of EU IP SCAPE project
- Jan: Kick-off meeting of ANR Geopeuple project
2010
- Dec: PhD Def. of D. Gorisse, HdR Def. of F. Precioso, PhD def. of JE. Haugeard
- Nov: HdR def. of Maria Rifki (Pres.), PhD of P. Massip
- Sept: ICIP in Hong Kong
- Sept: SCAPE new IP european project accepted
- Sept: Geopeuple new ANR project with EHESS and IGN accepted
- July: PhD Def of T. Napoleon (reviewer), K. Bailly (Pres.)
- June: PhD Def of Trinh-Minh-Tri Do (Pres.)
- June: 4 papers accepted to ICIP 2010
- April: invited seminar on similarity and scalability issues on CBIR at UniG university and at ECAIS
- March: My paper An Application of Swarm Intelligence to Distributed Image Retrieval (with Picard and Revel) accepted to Information Sciences Journal
- Feb: PhD Def of A. Bordes (Pres.), AM Tousch (reviewer)
Old News
2009
- Dec09: IUF nomination
PhD Def of M. Hanif, E. Aldea - Nov09: ASAP new ANR project on deep learning
3 papers presented in Egypt ICIP 09
PhD Def. of Corina Iovan
GdR ISIS workshop organisation on scalability and cross-media - Oct09: Organize Digital Video event in Sibgrapi09, Brazil
- Sept09: 2 papers in ISPRS workshop CMRT
Phd Def. of A. Auclair, MI. Akodjènou, J. Forest - March09: ITOWNS presentation in DAPA journey
- Feb09: 1 week invited at I2R Institute in Singapore
- Several Participations:
- Program committee of CMRT09
- Program committee of SinFra’09
- Technical program committee of The 15th International MultiMedia Modeling Conference (MMM2009) http://mmm2009.eurecom.fr/
- Program committee of CBMI 2009
- Program committee of the International Conference on Imaging Theory and Applications 2009 http://www.imagapp.org//cfp.htm
- Ad hoc reviewer for NSF, program 2009, USA
- Committee CR2/CR1 of l’INRIA Rocquencourt 2009
- Reference expert for Agropolis fondation, 2009
2008
- Dec08: seminar at LEAR lab.
- Presentation revue ANR
- Paper in ICPR 08 on fast LSH kernels
- Paper in ICIP 08 on distributed CBIR
- Paper in CIKM 08 on high-dim indexing
- Paper in TrecVid workshop TVS 08
- PhD Def. of Diane Larlus Nov 28, LEAR lab, INRIA Grenoble
- PhD Def. of David Picard Dec 5, ETIS lab
Some PhD thesis where I participated to the jury (or scheduled):
[2008] Nicolas Burrus
Apprentissage a contrario et architecture efficace pour la détection d’évènements visuels significatifs
[2008] Diane Larlus
Création et utilisation de vocabulaires visuels pour la catégorisation d’images et la segmentation de classes d’objets
Abstract:
This thesis deals with the interpretation of static images, with a focus on recognizing object categories. We consider several different approaches, which are all variations on the bag-of-words model, and all use local image descriptors. The first part of the thesis examines different methods for creating visual vocabularies. We aim to create vocabularies which perform well for image categorization. The first method proposed uses dense image representations. Feature descriptors are extracted and then quantized to visual words, using a two-stage clustering algorithm. We provide a full quantitative evaluation of the method. The second method we propose for creating visual vocabularies integrates the vocabulary into an image representation model. This generative model uses the image class labels via latent variables describing object aspect. Training the model leads to the creation of a compact and discriminative set of visual words. Next we show that traditional visual vocabularies (like the ones used above) can be replaced by random decision trees. Each tree provides a quantization of the space of descriptor representations into visual words. Since the trees are constructed using the image class labels, they have good classification performance. Each node uses a simple classifier, so processing of test images is fast. The random trees are also used for online learning of saliency maps which guide the process of descriptor sampling. The second part of the thesis deals with object category segmentation. We first present a method which uses an extended latent aspect based model. Instead of considering aspects at the image level, the method models them at the sub-region level. These semi-global regions can overlap and share information, allowing the local predictions to be improved. The local classifications are based on visual word statistics. The second segmentation method combines the low-level consistency properties of a Markov Random Field with an appearance model which provides higher-level constraints. The appearance model is based on regions which each represent a single object as a set of visual words. We also evaluate using decision trees instead of visual words. Finally, the method is applied to a real-world visual search problem for a humanoid robot. The method is used to generate hypotheses about the position of an object in the robot’s eld of view.
[2008] Karim Yousfi
Segmentation hiérarchique optimale par injection d’a priori radiométrique, géométrique ou spatial
[2008] Trang Vu
Apprentissage d’ordonnancements pour la constitution de Corpus d’evaluation et pour l’Agregation de listes en Recherche d’Information
[2008] Anne-Lise Chesnel
Damage assessment on buildings due to major disasters using very high resolution satellite multimodal images
[2008] Anastasia Krithara
Learning Aspect Models with Partially Labeled Data
Abstract:
Machine learning techniques have been used for various information access tasks, such as categorization, clustering or information extraction. Acquiring the annotated data necessary to apply supervised learning techniques is a major challenge for these applications, especially in very large collections. Annotating the data usually requires humans who can read and understand them, and is therefore very costly, especially in technical domains. Over the last years, two main approaches have been explored towards this direction, namely semi-supervised (SSL) and active learning. Both paradigms address the issue of annotation cost, but from two different perspectives. On the one hand, semi-supervised learning tries to learn by taking into account both labeled and unlabeled data. On the other hand, active learning tries to find the most informative examples to label, in order to minimize the number of labeled examples necessary for learning.
Either methods try to reduce the human labeling effort.
In this thesis, we address the problem of reducing this annotation burden. In particular, we investigate extensions of aspect models for the classification task, where the training set is partially labeled. We propose two semi-supervised PLSA algorithms, which incorporate a mislabeling error model. We then combine these semi-supervised algorithms with two active learning algorithms. Our models are developed as extensions of the classification system previously developed in Xerox Research Centre Europe. We evaluate the proposed models in three well-known datasets and in one coming from a Business Group of Xerox.
[2008] Eric Galmar
Representation and Analysis of Video Content for Automatic Object Extraction
Abstract:
The recent explosion of multimedia applications has called for an increasing demand of advanced search and indexing of multimedia information. Among them, digital video content is certainly one of the most complex to analyze and represent. From this point of view, video objects are considered as essential elements for handling video contents, as they provide accurate and flexible representation for numerous applications such as semantic content analysis or video coding.
Automated object extraction from videos is a difficult task that has been widely addressed in the past years in the context of MPEG-4 video coding. Methods developed so far mostly rely on motion estimation to define the object model and adapt this models frame to frame. However there is an agreement that robustness of motion and the accuracy of the support are dependent to each other. In this thesis, we first introduce a framework for video object modeling based on a spatiotemporal representation with graphs. The model describes both the internal structure of object regions and their spatiotemporal relationships inside the shot. This approach is fully supported by the MPEG-7 multimedia standard, where the information is structured hierarchically in scenes, shots, objects and regions. As the next step, we propose a 2D+T scheme for the extraction of spatiotemporal volumes. The method we developed uses local and global properties of the volumes to propagate them coherently in space and time. At this point we investigate grouping of spatiotemporal regions into complex objects using motion models. To address the difficulty of building motion models, we propose a method to propagate and match moving objects to areas where motion information is less relevant. In a third step, we investigate the benefit of semantic knowledge for spatiotemporal segmentation and labeling of video shots. For this purpose we extend a knowledge-based system providing fuzzy semantic labeling of image regions to video shots. The shot is split into smaller block units and, for each block, volumes are sampled temporally into frame regions that receive semantic labels. The semantic labels are then propagated within volumes and a consistent labeling of the shot is finally obtained by joint propagation and re-estimation of the semantic labels between the temporal segments. Finally, we explore the capabilities of the representation for indexing and retrieval tasks. We first consider the context of a region-based indexing framework called the Vector Space Model. We present a study of the model properties and show that the spatiotemporal representation gives more robustness to the visual signatures compared to the traditional keyframe representation. This dissertation concludes by proposing a strategy to compare efficiently object graphs. To this aim we introduce a similarity measure between graphs that we further use to search for a given object.
[2008] Lech Szumilas
Scale and Rotation Invariant Shape Matching
Abstract:
Recognition of objects from images is one of the central research topics of computer vision.
The use of shape for recognizing objects has been actively studied since the beginning of object recognition in 1950s. Several authors suggest that object shape is more informative than its appearance – the object appearance properties such as texture and color vary between object instances more than the shape e.g. bottle, caps, cars, airplanes, cows, horses etc. Recent methods are concentrated on extracting shape features and learning the object models directly from images which impose such problems as object occlusion,
incomplete and often fragmented object boundaries, varying camera view-points. While these approaches are designed to learn object models from fragmented and incomplete object boundaries, achieving invariance to rotation, scale and affine transformations has not been fully solved.
This thesis address the problem of learning object models that use shape properties with full rotational and scale invariance. A new approach is proposed where invariance to image transformations is obtained through invariant matching rather than typical invariant features. This philosophy is especially applicable to shape features, represented by edges detected in images which do not have a specific scale or specific orientation until assembled into an object. Our primary contributions are: a new shape-based image descriptor that encodes a spatial configuration of edge parts, a technique for matching descriptors that is rotation and scale invariant and shape clustering that can extract frequently appearing image structures from training images without a supervision. This thesis also presents an overview of the object recognition field and our other contributions in the area of local appearance based methods, texture detection and image segmentation.
Keywords: object recognition, shape, image descriptors, interest points.
[2008] Avik Bhattacharya
Indexing of satellite images using structural information
Abstract:
From the advent of human civilization on our planet to modern urbanization, road networks have not only provided a means for transportation of logistics but have also helped us to cross cultural boundaries. The properties of road networks vary considerably from one geographical environment to another. The networks pertaining in a satellite image can therefore be used to classify and retrieve such environments. In this work, we have defined several such environments, and classified them using geometrical and topological features computed from the road networks occurring in them. Due to certain limitations of these extraction methods there was a relative failure of network extraction in some urban regions containing narrow and dense road structures. This loss of information was circumvented by segmenting the urban regions and computing a second set of geometrical and topological features from them […].
Keywords : Satellite images, road networks, urban regions, classication, indexing.
[2007] Thomas Retornaz
Automatic detection of text from natural scenes. A semntic descriptor for content based image retrieval
Abstract:
Multimedia data bases, both personal and professional, are continuously growing and the need for automatic solutions becomes mandatory. Effort devoted by the research community to content-based image indexing is also growing, but the semantic gap is difficult to cross: the low level descriptors used for indexing are not efficient enough for an ergonomic manipulation of big and generic image data bases. The text present in a scene is usually linked to image semantic context and constitutes a relevant descriptor for content-based image indexing.
In this thesis we present an approach to automatic detection of text from natural scenes, which tends to handle the text in different sizes, orientations, and backgrounds. The system uses a non linear scale space based on the ultimate opening operator (a morphological numerical residue). In a first step, we study the action of this operator on real images, and propose solutions to overcome these intrinsic limitations. In a second step, the operator is used in a text detection framework which contains additionally various tools of text categorisation.
The robustness of our approach is proven on two different dataset. First we took part to ImagEval evaluation campaign and our approach was ranked first in the text localisation contest. Second, we produced result (using the same framework) on the free ICDAR dataset, the results obtained are comparable with those of the state of the art. Lastly, a demonstrator was carried out for EADS. Because of confidentiality, this work could not be integrated into this manuscript.
[2007] Laurence Boudet
Qualification automatique de modèles 3D de bâtiments à partir d’images aériennes haute résolution
[march 2006] Roger Trias Sanz
[pdf] Semi-automatic high-resolution rural land cover classification
[nov 2006] W. Touhami
Identification et classification automatique de régions d’intérêt dans des images tomographiques : application aux kystes du rein
[dec 2005] Seriy Kosinov
Machine Learning Approach to Semantic Augmentation of Multimedia Documents for Efficient Access and Retrieval
[june 2005] Nesrine Chehata
Modélisation 3D de scènes urbaines à partir d’images satellitaires à très haute résolution
[may 2005] Greet Frederix
Beyond Gaussian Mixture Models: Unsupervised Learning with applications to Image Analysis